Introduction¶
The Ocean Data Explorer is a data exploration tool with a customized public web interface that allows scientists, managers, and the general public to discover and access public data.
The Ocean Data Explorer has 3 major components:
Data Catalog
Data Map
Data Views
See the following sections of this help documentation for more information about each of these components:
Catalog Overview¶
The catalog provides searchable access to all datasets within the Ocean Data Explorer. The catalog can be used to discover, browse, and download data files. Additionally, the catalog can be used to add some data layers to the data map.
Data Types¶
The catalog contains several observational data types:
Real-time data are ingested, served, and displayed by the Ocean Data Explorer at the same frequency the data are collected (and sometimes reported) by the originator with little to no delay. Examples of real-time assets include weather stations, oceanographic buoys, and webcams.
Near real-time data are ingested by the Ocean Data Explorer at the same frequency that the data are made available; however, there is some delay (hours to days) between data are collected and when the data are made available by the provider. Examples of near real-time assets include satellite images and derived satellite products.
Historical data are data that are one month old or older. Historical data are ingested by the Ocean Data Explorer upon stakeholder request, either from an associated campaign in the Research Workspace, or from national archives. Examples of historical data include species abundance surveys and similar research efforts.
For more details, please see the Download Historical Sensor page.
Interface¶
Within the catalog, you will find a listing of all the data layers accessible through the Ocean Data Explorer. By default, the data layers are shown in alphabetical order. The data catalog is built around a familiar search interface, with several important elements arranged around the screen:
Filter by result type icons in the upper left (Data Layers, Projects, and Sensor Stations).
Advanced search options below that (Spatial filter, Filter time, Access method).
Filter by tag in the column on the left.
A list of datasets that match your search criteria in the center of the page.
For more details on how to search the catalog, please see the Search the Catalog page.
Visualizing Data¶
If a dataset can be visualized in the Ocean Data Explorer’s map interface, you will see a globe icon ![]() to the left of the dataset’s name. Clicking on the
to the left of the dataset’s name. Clicking on the ![]() button will add it to the map.
button will add it to the map.
For datasets with multiple layers, click the ![]() button then select individual layers using the
button then select individual layers using the ![]() .
.
Before visualizing, you can learn more about a dataset by clicking on the title to view the metadata page.
Layer Metadata¶
A dataset’s metadata page displays the URL to the source data, a data description, and any usage notes. There will also be an inset map where you can explore the dataset as a single layer. If the data layer is a timeseries dataset, you will be able to move back and forth through time using the time slider at the bottom of the inset map.
Some data layers in the catalog have more than one variable associated with them. In these cases, a thumbnail image will appear below the data layer in the catalog and in the metadata view. To learn more about each of the data layer variables, click on the title below the thumbnail image. You will be taken to a metadata page that shows the URL to the source data, the data description, and any usage notes. The variable will also appear in the inset map where you can explore the data as a single layer.
More Information¶
In addition to metadata, contextual information about the instrumentation may be found under the ‘More Information’ tab. This may include information such as: instrument location, deployment depth, technical specifications, calibration, and instrument photos or diagrams.
Download Data¶
In addition to visualizing a dataset you can download datasets by clicking the download button ![]() and selecting among the options in the popup window. Data files may be accessed using interoperability services (i.e. ERDDAP, THREDDS), downloaded individually in different file formats, or bundled for download using the Download Queue. See below for more information about data format.
and selecting among the options in the popup window. Data files may be accessed using interoperability services (i.e. ERDDAP, THREDDS), downloaded individually in different file formats, or bundled for download using the Download Queue. See below for more information about data format.
Data Formats¶
There are several ways to download gridded data from the Ocean Data Explorer:
THREDDS
NetCDF Subset
ERDDAP
OPeNDAP
WMS
THREDDS¶
Thematic Realtime Environmental Distributed Data Services (THREDDS) is a set of services provided by Unidata that allows for machine and human access to raster data stored in NetCDF formats. THREDDS provides spatial, vertical, and temporal subsetting, as well as the ability to select individual dimension or data variables to reduce file transfer sizes. The most commonly used THREDDS services for users are NetCDF Subset, and Open-source Project for a Network Data Access Protocol (OpenDAP).
Note
All THREDDS servers have a bandwidth limit, and it will not allow you to download more than the cap in one go. So you won’t be able to download 1 Tb of data with a single request. If you need a lot of data, you will need to break up your requests to download the dataset incrementally (e.g., one month at a time; one variable at a time, etc.). If you’re grabbing a lot of data programmatically, sometimes it’s easiest to grab just one time slice at a time using a loop.
NetCDF Subset¶
The NetCDF Subset protocol looks through all the datasets NetCDF files stored on our server, and provides an human-readable or machine-readable interface to subset the data by time, geography, or variable. For more information, please see the Download Using NetCDF page.
Tip
When you initially request a dataset via NetCDF Subset, the server may take a long time to respond if the dataset is large (i.e., thousands of files). Be patient, it’s not broken! If your web browser times out (e.g., after 10 minutes of waiting), you can try reloading or just giving it a few more minutes and then reload. This won’t restart the server process, and once it’s indexed all the files things will go pretty fast.
ERDDAP¶
The ERDDAP (National Ocean and Atmospheric Administration’s Environmental Research Division’s Data Access Program) Server is a free and open-source Java “servlet” that converts and serves a variety of scientific datasets using common file formats. ERDDAP gives you a simple, consistent way to download subsets of datasets in common file formats, in addition to making graphs and maps. All information about every ERDAPP request is contained in the URL of each request, which makes it easy to automate searching for and using data in other applications. Proficient users can build their own custom interfaces. Many organizations (including NOAA, NASA, and USGS) run ERDDAP servers to serve their data. Because of its widespread use and accessibility, the ERDDAP principal developer and user community have created user guides, instruction videos, and code examples to facilitate access by new users.
OPeNDAP¶
OPeNDAP is a simpler THREDDS protocol that can provide ASCII (human-readable) or binary files. It loads very quickly, but doesn’t do any interpretation for you at all and you will need to be able to calculate or surmise the indices you need to subset the data. For example, if there are 20,000 dates listed in the file, it will give you the option of selecting 0-20,000, but it won’t tell you what those dates are. Therefore, OPeNDAP is best in cases where you are already familiar with the dataset’s bounds and speed is more important, or in cases where you just want to download the whole thing and don’t care much about subsetting.
Note
All THREDDS servers have a bandwidth limit, and it will not allow you to download more than the cap in one go. So you won’t be able to download 1 Tb of data with a single request. If you need a lot of data, you will need to break up your requests to download the dataset incrementally (e.g., try downloading half a variable first, then the second half, or one variable at a time, etc.).
For more details, please see the Download Using OpeNDAP page.
WMS¶
Web mapping services (WMS) are used to provide machine access to images used by remote mapping programs (e.g., tiling services). Accessing programs use GetCapabilities requests to ask for image data in whatever format they require, which allows them to gather image tiles over specific areas with the projections, styles, scales and formats (PNG, JPG, etc.) that fits their needs.
Selecting WMS (Web Mapping Service) under the Download button will start the WMS service. The returned image will be projected according to the parameters set in the URL. In the example below, modifying either the parameters (e.g., changing the WIDTH, COLORSCALERANGE values) or the projection will redraw the image for your mapping service.
For more details, please see the Download Using WMS page.
Virtual Sensors¶
For details on how to download data from virtual sensors, please see the Download Virtual Sensor Data page.
Parsed Data¶
This section of our documentation is still under development. For assistance, please contact us via the Feedback button ![]() .
.
NetCDF Resources¶
NetCDF is the name of a file format as well as a grouping of software libraries that describe that format. The files have the ability to contain multidimensional data in a wide variety of data types, and they are highly optimized for file I/O. This makes them excellent at storing extremely large datasets because they can be quickly and easily sliced without putting the entire dataset into RAM.
In addition, NetCDF files can contain metadata attributes that describe any time components, dimensions, units, history, etc. Because of this, NetCDF is often called a self-describing data format and they are excellent for holding archived data, and they are the primary format preferred by the National Centers for Environmental Information (NCEI, formerly NODC).
NetCDF libraries are available for every common scientific programming language including Python, R, Matlab, ODV, Java, and more. Unidata maintains a list of free software for manipulating or displaying NetCDF data. A good, simple program to start exploring NetCDF data is Unidata’s ncdump, which runs on the command line and can quickly output netCDF data to your screen as ASCII. Unidata’s Integrated Data Viewer or NASA’s Panoply are free, relatively easy programs to use that will display gridded data, though they are not as straightforward to use as a scientific programming language.
Map Overview¶
The map interface provides interactive data exploration, mapping, and charting. All real-time and near real-time data within the Ocean Data Explorer are accessible as interactive visualizations in the map.
The map is highly customizable via the Settings and Legend menus to enable deep exploration of the data. Advanced charting features allow you to view and summarize multiple datasets, and to create custom Data Views to compare data sources, bin by time, or plot climatologies and anomalies of timeseries datasets.
Datasets listed in the catalog that can be viewed in the map are indicated by the globe icon ![]() .
.
Additionally, you can use the map to create and share custom compilations of biological, sensor, and model outputs to spotlight environmental events or geographic locations.
For more details, please see the View Layer Metadata page.
The data map is built around a familiar interactive map interface, with several important elements arranged around the screen:
Blue toolbar across the top
Legend displayed on the right
Grey time slider toolbar along the bottom
Data display window in the bottom left corner
Zoom navigation tools in the top left corner
Real-Time Data¶
Real-time data are ingested, served, and displayed in the Ocean Data Explorer at the same frequency the data are collected (and sometimes reported) by the originator with little to no delay. Examples of real-time assets include weather stations, oceanographic buoys, and webcams. For the purposes of this documentation, it’s helpful to understand how the following real-time data terms are defined:
Term |
Definition |
|---|---|
Hexagonal bin |
A group of stations that are aggregated into a hexagon for visual summary. |
Station |
A device that collects data related to the weather and environment using many different sensors (e.g. weather station). |
Sensor |
An individual measurement device affixed or associated with a station (e.g. thermometer, barometer). |
Parameter |
The type of value measured by the sensor (e.g. temperature, pressure). |
Real-time data from observation stations are aggregated into hexagonal bins to visually summarize data over a large spatial area when the map is zoomed out. This means that data from more than one station may be displayed within a hexagon. The color of the hexagon represents the average value of the selected sensor parameter within that hexagon. For example, if air temperature is the selected sensor type, then the hexagon color will reflect the average temperature for all stations within that bin.
To view a summary of the station data contained within a hexagon, hover your mouse over the hexagon. The number of stations aggregated within that hexagon will be displayed as n stations. The average value for the selected sensor type will be also be shown, followed by the time range for which that value was measured. If there are not more than one station aggregated within a hexagon, the hover-over view will display the value for the selected parameter, followed by a list of the other sensor types associated with that station and the range of associated data. By default, only five of the sensors are shown in the hover window. More sensors are indicated by the n more sensors in the lower left of the window.
To view data for an individual station, zoom in on the map. The hexagons will soften into points that represent the individual stations that were aggregated into that hexagon. To view current readings from that station, hover over its point. As shown in the image below, a pop-up window will display some basic information about the station, including its name, data source affiliation(s), latitude and longitude, current readings, and available sensor parameters (e.g., air temperature, water level, and water temperature as in the example below).
To view station data, click on the point. As shown in the image below, data from the station will appear in the data display window in the lower left corner of the window. You can use the dropdown menu in the data display window to select data from different sensors, and you can use the Time Slider to adjust the time period of the data.
Near-Real-Time Data¶
Near-real-time data are ingested by the Ocean Data Explorer at the same frequency that the data are made available; however, there is some delay (hours to days) between data collection and when the data provider makes it available. Examples of near real-time assets include model outputs, satellite images, and derived satellite products.
Model and Satellite Data¶
Model outputs or satellite imagery have been visually abstracted in the portal to include a schematic representation of the data attributes or variables. The variable currently being displayed is shown as a title in the right hand legend bar. The variable being displayed can be changed by clicking the caret icon and selecting from the other variables that may be available (note: the variables available will vary depending on which data layer you are viewing). The current date and time for the data being displayed is shown in the right hand legend bar beneath the data layer title.
To select your area of interest, use the pan and zoom features on the map. To display values within your area of interest, hover your mouse over the map. The name of the data layers, latitude/longitude, date, time, and the value at the given location will appear. If you click on the map in any location covered by a multi-dimensional model or grid, a data chart window showing the data trends over time will appear. More information can be found in the Data Charts section of this document.
The timer slider bar at the bottom of the map can be used to view the various time intervals of data available. The interval available will vary depending on which data layer you are viewing. More information about using the time slider can be found in the Time Slider section of this documentation. Depending on your zoom level and internet speed, these time intervals layers could take awhile to appear so be patient as these layers load. Once you do have them in the cache they will load more quickly as you step forward and backwards through the time.
The data layer legend on the right hand shows the color scale that is used to represent the unit of measurement. You can change the palette and scale settings by clicking on the color bar. Select among the different color palettes using the drop down menu. The legend scale can be changed by either adjusting the scale slider, or by clicking on the gear icon and entering or advancing the bounds control interval. When the map is zoomed in, the scale and color for that area can be automatically set for the data in view by clicking the Autoset for data view button.
Historical Data¶
Historical data are data that are one month old or older. Historical data available through the portal were sometimes collected in real-time and subsequently archived; other historical data are ingested from local or national archives upon stakeholder request.
Biological Observations¶
These features and more will be explored more thoroughly in upcoming updates to this documentation.
Data from most research-based biological observations are aggregated into hexagonal bins to visually summarize data over a large spatial area when the map is zoomed out. This means that data from more than one location or observation may be displayed within a hexagon. The color of the hexagon represents the average value of the selected data parameter within that hexagon. For example, if count or abundance is the selected parameter, then the hexagon color will reflect the average count of all individuals or observations within that bin.
To view a summary of all the observation data contain within a hexagon, hover over the hexagon. A window will appear showing the summary of all observations by parameter. Additionally, the time range for which those values were measured will be shown. If you click on the hexagon, a data display window will appear showing a histogram chart summarizing the data. The number of locations or observations aggregated within that hexagon will appear below the parameter name in the data display chart.
To view data for an individual location or observation, zoom in on the map. The hexagons will soften into points that represent the individual sample locations or observations that were aggregated into that hexagon. To view current readings from that location, hover over its point. As shown in the image below, a pop-up window will display some basic information, including the observation or location name, latitude and longitude, and a summary of events or observations by parameters (e.g., count by species, percent abundance, number of events, etc ).
To change the data parameters in the map, the filters can be used in the legend on the right side. You can select among the measurements that are available using the caret, or by toggling on/off the checkboxes. The exact filters or measurements available vary by the data layer being shown.
To further interact with the data in the map, the Polygon Tool can be used to create summary statistics across spatial areas of interest. Or, the Time Slider bar can be used to view the various time intervals of data available.
If when zoomed in the hexagons do not soften into points, the individual locations or observations have been intentionally aggregated for data use or confidentiality purposes.
To view location data, click on the point. Data from that location will appear in the data display window in the lower left corner of the window. You can use the dropdown menu in the data display window to select different parameters for that location (if available), or you can use the time slider to adjust the time period of the data.
Customize Data in the Map¶
You can view and interact with the data in a number of ways. As with other interactive maps, you can pan and zoom to adjust the view to your area of interest. Additionally, you can click on a data point of interest to open a chart that summarizes the data. A time slider at the bottom of the map can be used to move back and forth through time for timeseries data. More information about these features is provided below.
Filter Data¶
In the map, your selected layers will appear in a legend on the right. The filters in the legend can be used to change the parameters on the map. You can select among the measurements that are available using the caret, or by toggling on/off the checkboxes. The exact filters or measurements available vary by the data layer being shown.
Toggle Layers On/Off¶
Individual data layers can be toggled on and off using the``Eyeball`` icon to the right of the data layer name. To delete the data layer from the map, select the X icon.
Change Layer Order¶
The order in which data layers appear in the map can be changed. By default, the data layer that appears at the top of the map legend will be displayed forward in the map. To move data layers backward in the map, select the Up/Down Arrow to the left of the data layer name.
Customize Color and Scale¶
The data layer legend on the right hand side shows the color scale that is used to represent the unit of measurement. You can change the palette and scale settings by clicking on the color bar. Select among the different color palettes using the drop down menu. The legend scale can be changed by either adjusting the scale slider, or by clicking on the gear icon and entering or advancing the bounds control interval. When the map is zoomed in, the scale and color for that area can be automatically set for the data in view by clicking the Autoset for data view button.
For more details, please see the Customize Layers page.
Search and Add Layers¶
From the map, you can search for and add additional data layers to the map. Click on the catalog button in top right to return to the catalog page you most recently visited. You can also search for additional data layers to add to the map using the search bar at the top left corner. When you have selected additional layers, click Map to return to the map.
For more details, please see the Add Layers page.
Time Slider¶
The time slider bar at the bottom of the map allows you to view temporal data. The time intervals available will vary depending on which data layer you are viewing. The bar is unavailable if there is not any time-enabled data layers loaded. By default, the time slider is set to display the most recent data that is available for that data layer.
Tip
For quick reference, the time range for data being viewed in the map is shown in the right-hand map legend beneath the data layer title.
The temporal extent for the data layers can be viewed by hovering your mouse over the time slider control. The name ofthe data layer, the begin and end dates for the data, and a line graph of the temporal range will appear. The temporal information will appear for all time-enabled datasets that are currently loaded in the map. For more details, please see the How To Time Slider page.
Depth Filter¶
The depth slider bar located in the bottom right of the map allows you to filter data across the water column. The depth intervals available will vary depending on which data layer you are viewing. The bar is unavailable if there is not any depth-enabled data layers loaded. By default, the depth slider is set to display all data across the water column.
Tip
For quick reference, the depth range for data being viewed in the map is shown in the right-hand map legend beneath the time extent.
For more details, please see the Filter by Depth page.
For other ways to filter data in the map, please see the Filter Data page.
Polygon Tool¶
To further interact with data in the map, the polygon tool can be used to create summary statistics across spatial areas of interest.
For more details, please see the Polygon Tool page.
Data Charts¶
The catalog and map offer multiple ways of comparing data within both the mapped interface and within a Data Views.
Different Chart Types¶
This section includes descriptions for the common charts used to display data in the portal. Data charts can be accessed both by clicking a point on a data layer in the map, or by using the custom Data Views interface.
Categorical Variables¶
Bar charts: compare the size or frequency of different categories. Since the values of a categorical variable are labels for the categories, the distribution of a categorical variable gives either the count or the percent of individuals falling into each category.
Quantitative Variables¶
Line charts: display points connecting the data to show a continuous change over time. In the map, the line chart shows the current values together with historical statistics. The x-axis shows the occurrences and the categories being compared over time and the y-axis represents the scale, which is a set of numbers organized into equal intervals.
Histograms: show the frequency of distribution for the observations. A histogram is constructed by representing the measurements or observations that are grouped on a horizontal scale, the interval frequencies on a vertical scale, and drawing rectangles whose bases equal the class intervals and whose heights are determined by the corresponding class frequencies.
Box plots: are useful for identifying outliers and for comparing distributions. The boxplot is a graph of a five-number summary: the minimum score, first quartile (Q1-the median of the lower half of all scores), the median, third quartile (Q3-the median of the upper half of all scores), and the maximum score. The boxplot consists of a rectangular box, which represents the middle half of all scores (between Q1 and Q3). Approximately one-fourth of the values should fall between the minimum and Q1, and approximately one-fourth should fall between Q3 and the maximum. A line in the box marks the median. Lines called whiskers extend from the box out to the minimum and maximum scores.
Dot plots: consist of data points plotted on a fairly simple scale. Dot plots are suitable for small to moderate sized data sets to highlight clusters and gaps, as well as outliers. When dealing with larger data sets (around 20–30 or more data points) the box plot or histogram may be more efficient, as dot plots may become too cluttered after this point.
Curtain plots: show a visual summary of vertical profiling data. If data is available at depth, the chart will show depth on the y-axis with the values represented by colors.
For more details, please see the Customize Data Charts page.
Climatology and Anomaly Charts¶
If there are more than three years of data coverage, charts show statistics from past weather patterns along with the current data. These are not officially climatologies, which typically require 30 years of data, but they can still be useful to quickly compare how the current year compares to the long-term average.
Observational Statistics¶
By default, if there are too many observations to easily show on the time-series, the observations binned by default for display. Graphs may show the following:
Mean: The mean line represents the average value of all observations within each time bin.
Min/Max envelope: The envelope represents the extent of observations within each time bin.
Interannual Statistics¶
Interannual statistics are calculated on physical time-series where available data coverage in the system is longer than three years. Statistics are derived for days, weeks, months, seasons, and years based on the Gregorian calendar by:
binning the observations into the selected time periods,
combining the time bins across years (e.g, for daily bins, combining all data from April 13th regardless of year; for monthly bins, combine all data from all Aprils), and
calculating statistics for each interannual time bin.
For interannual statistics, we calculate the following:
Mean: The mean represents the average value of all observations within each time bin, across all recorded years.
Low: The low represents the minimum value of all observations within each time bin, across all recorded years.
High: The high represents the maximum value of all observations within each time bin, across years.
Mean to 10%, Mean to 90%: Percentiles are calculated by ordering all values in the time bin across all recorded years and selecting the value at the 10% and 90% locations in the array (i.e., the shaded percentile region relays what the typical temperature is at that time of year excluding the 10% most extreme values on either end of the distribution).
Anomaly Plots¶
Anomalies are available wherever interannual statistics are available (i.e., in all time-series where available data coverage in the system is longer than three years, but are only available on data binned on days or more).
Anomalies are calculated by calculating the mean value of the observational bin and subtracting the interannual statistical bin for that time period. For example, the daily anomaly for April 13th, 2016 is calculated by taking the average temperature for that day minus the mean interannual April 13th temperature.
Customize Data Charts¶
The table below contains a key to several of the important terms used in describing the Ocean Data Explorer’s chart capabilities:
Term |
Description |
|---|---|
Minimum |
The minimum value of the entire time-series within each bin, represented by a dashed blue line. |
Mean to the 10th percentile |
The range from the mean to the 10th percentile of the data is represented by a blue shaded area. |
Mean |
The mean of the entire time-series within each bin, represented by a dashed gray line. |
Mean to the 90th percentile |
The range from the mean to the 90th percentile of the data is represented by a red shaded area. |
Maximum |
The maximum value of the entire time-series within each bin is represented by a dashed red line. |
Line chart |
A chart of the current values with historical statistics. |
Climatology |
Year-to-date monthly mean values of the current year compared to historical statistics. |
Anomaly |
The data values minus the mean values across all years. |
Curtain |
If data is available at depth, the chart will show depth on the y-axis with the values represented by colors. |
Time Bins¶
Data can be binned across years within the following time periods:
Time period |
Definition |
|---|---|
All |
No binning. |
Hours |
Data are binned by hour and daily statistics are displayed (see below). |
Days |
Data are binned by day and statistics are by day number across years. |
Weeks |
Data are binned by week, and statistics are by week number across years. |
Months |
Data are binned by month, and statistics are by month number across years. |
Seasons |
Data are binned by northern hemisphere seasons defined as the following:
|
Years |
Data are binned by years, and statistics are across years. |
Note
Percentiles are calculated by ordering all values in the time bin across all recorded years and selecting the value at the 10% and 90% locations in the array. I.e., the shaded percentile region is telling you what the typical temperature is at that time of year excluding the 10% most extreme values on either end.
For more information on how to customize charts, refer to the Customize Data Charts section.
Quality Control (QARTOD)¶
Quality control algorithms are run on datasets and quality flag results are shown for visual exploration. The data quality procedures meet the U.S. Integrated Ocean Observing System (IOOS) Quality Assurance of Real Time Ocean Data (QARTOD) maintained through the IOOS QC library (ioos_qc). The automated QC algorithms do not screen out or delete any data, or prevent it from being downloaded. The algorithms only flag “suspect” or “fail” data points for visualization and deliver those flags as additional variables in downloaded data.
Roll up quality flags summarizing pass, suspect, and failed values can be seen under Inventory.
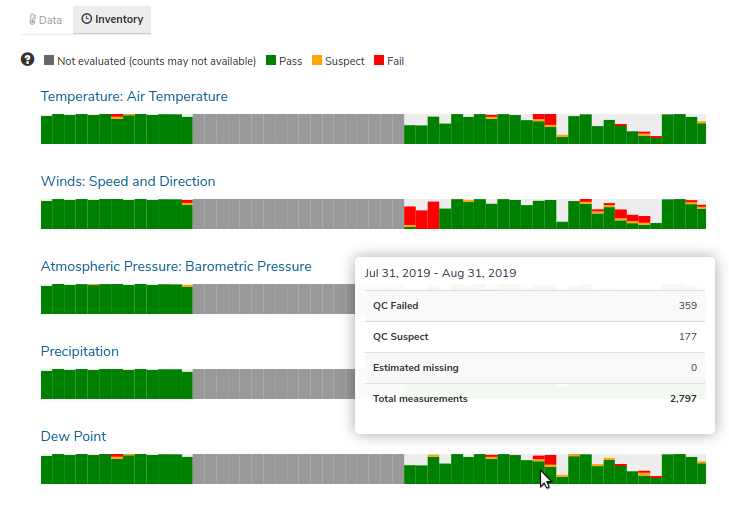
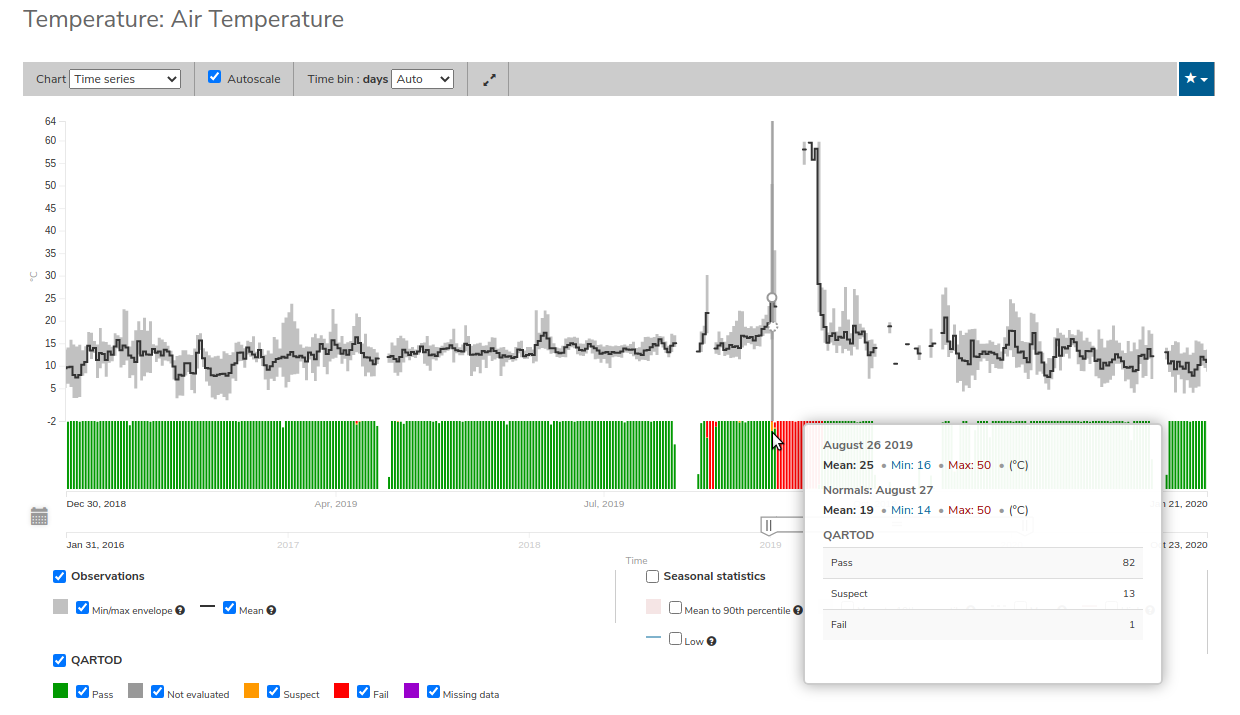
Data quality flags for individual data points can be seen within the data charts. Documentation of the test code and thresholds are linked to under QC information in the lower left of the chart.
Download Data¶
Data may be downloaded through the data catalog, as described in the Download Data section.
Data Views Overview¶
You can save a collection of data layers and visualize them together for comparison and analysis. These collections are called data views, and they are accessed by clicking on the views button ![]() in the toolbar along the top of the window.
in the toolbar along the top of the window.
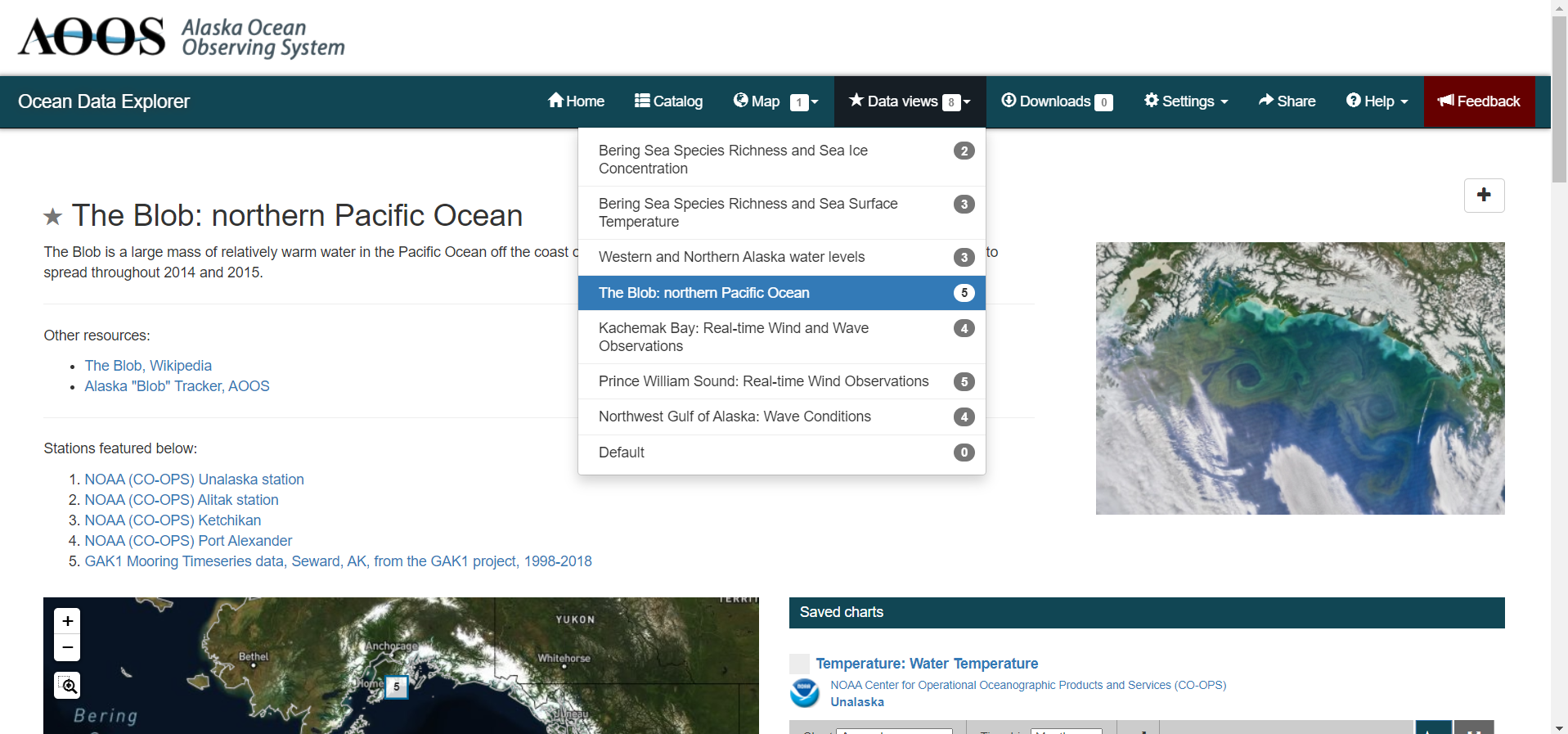
Within the portal there are several pre-made data views that highlight environmental events or locations of interest. You can access these pre-made views from the portal landing page or by clicking on the views button ![]() and selecting a view from the dropdown menu
and selecting a view from the dropdown menu
The view will open, displaying data comparison charts for you to explore, as seen in the example below.
Note
If you need assistance creating a particular view, please contact us via the feedback button ![]() in the top right corner of the upper toolbar.
in the top right corner of the upper toolbar.
For more details, please see the Data Views section of the Data Views How-To page.